 Pré processamento dos Dados
Pré processamento dos Dados

Nesta parte do projeto será realizado a modelagem de dados, como: Data Cleaning e Data Wrangling e enriquecimento da dados, utilizando linguagem Python para futura análise exploratória.
1. Carregando a Base de Dados
1.1 Para coletar o dados basta entrar no link: SINE, e realizar o download do arquivo:
df = pd.read_csv("Dados/D_ETL_IMO_EXTRACAO_SINE_ABERTO_TRABALHADORES_SC.csv",
sep = ";", encoding='latin-1')
df_CBO = pd.read_csv('Dados/cbo.csv',sep=';', encoding = "ISO-8859–1")
Ao colocar o comando abaixo, observa-se a quantidade de observações e variáveis.
df.shape# (458965, 20)
O conjunto de dados possuem 458.965 observações (linhas) e 20 variáveis (colunas)
Abaixo segue amostra do conjunto:
df.head(2)| NACIONALIDADE | DEFICIENCIAS | BAIRRO | CEP | CODIGO_MUNICIPIO_IBGE | NOME_MUNICIPIO | UF | ESCOLARIDADE | ESTUDANTE | CURSOS_PROFISSIONALIZANTES | GRADUACOES | POS_GRADUACOES | IDIOMAS | HABILITACAO | VEICULOS | DISP_VIAJAR | DISP_DORMIR_EMP | DISP_AUSENTAR_DOMIC | PRETENSOES | MUNICIPIOS_INTERESSE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ESTRANGEIRA | NaN | BARRAGEM | 89165108.0 | 421480 | RIO DO SUL | SC | Médio Completo | N | TÉCNICO EM ELÉTRICA/REFRIGERAÇÃO | NaN | NaN | NaN | Nenhum | N | S | S | S | 414105-Almoxarife(N,15,0,Indiferente)|(...) | NaN |
| 1 | BRASILEIRA | NaN | CAMINHO NOVO | 88132373.0 | 421190 | PALHOCA | SC | Médio Completo | S | NaN | NaN | NaN | Inglês Básico | A | S | S | S | S | 414105-Auxiliar de almoxarifado(N,149,0,Indiferente)| (...) | NaN |
1.2 Sample dos Dados
Amostra aleatória com proporção de 30% do conjunto de Dados.
df_fatia = df.sample(frac=0.3, replace = False, random_state = 1)df_fatia.shape# (137.690, 20)
Para salvar este novo conjunto de dados, basta seguir a instrução abaixo.
df_fatia.to_csv('df_fatia.csv', index = False)2. Limpeza dos Dados
2.1 Carregando Bibliotecas e Carregando os dados:
Para iniciar o trabalho é preciso carregar algumas bibliotecas:
import pandas as pdimport reimport unidecodeimport matplotlib as pltCarregando o conjunto de dados
O conjunto de dados pib_cidade.csv, retirado do Wikipedia, consta no Github, repositório do projeto.
df_fatia = pd.read_csv('df_fatia.csv')pib = pd.read_csv('pib_cidade.csv', sep = ';', encoding='latin1')2.2 Excluindo alguns registros
Na coluna ESCOLARIDADE foi removido, todos os registros classificado como: Não identificado (6,43% do nosso conjunto de dados). Conforme podemos ver abaixo:
| Perc. (%) | |
|---|---|
| Médio Completo | 52.41 |
| Fundamental Completo | 11.13 |
| Médio Incompleto | 10.62 |
| Superior Completo | 7.92 |
| Não Identificado | 6.49 |
| Superior Incompleto | 6.43 |
| Fundamental Incompleto | 3.01 |
| Nenhum | 1.20 |
| Analfabeto | 0.36 |
| Especialização | 0.34 |
| Mestrado | 0.07 |
| Doutorado | 0.01 |
Na coluna NACIONALIDADE também removido todos os registro que foram classificados como IGNORADOS (11,76% do nosso conjunto de dados).
| Perc. (%) | |
|---|---|
| BRASILEIRA | 86.11 |
| IGNORADO | 11.76 |
| ESTRANGEIRA | 1.98 |
| NATURALIZADO BRASILEIRO | 0.09 |
| BRASILEIRO NASCIDO NO EXTERIOR | 0.07 |
2.3 Criando Colunas Numéricas:
Na coluna ESTUDANTE, possue duas classificações: Estudante ("S") e Não Estudante ("N"). Será criada uma coluna do tipo numérica, sendo 1 para estudante e 0 para não estudante.
df['Estudante'] = Nonedf['Estudante'] = df['ESTUDANTE'].apply(lambda x: 1 if x == 'S' else 0)Segue a coluna abaixo:
df_fatia[['ESTUDANTE','Estudante']].tail(3)| ESTUDANTE | Estudante | |
|---|---|---|
| 137686 | N | 0 |
| 137687 | S | 1 |
| 137688 | N | 0 |
df_fatia['Estudante'].value_counts()# 0 125131 # 1 12558Name: Estudante, dtype: int 64
estudante = df_fatia['ESTUDANTE'].value_counts()ax = estudante.plot(kind = 'barh', color = ['red','blue'], title = 'Quantidade de Cantidade Estudantes e \n Não Estudantes', xlabel = "Categoria")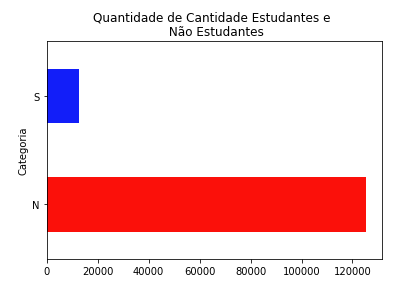
O mesmo ocorrido para a variável Estudante serão desenvolvido nas seguintes variáveis: 'VEICULOS', 'DISP_VIAJAR', 'DISP_DORMIR_EMP', 'DISP_AUSENTAR_DOMIC' e 'ESCOLARIDADE'.
df_fatia['Veiculo'] = Nonedf_fatia['Veiculo'] = df_fatia['VEICULOS'].apply(lambda x: 1 if x == 'S' else 0)df_fatia['Viajar'] = Nonedf_fatia['Viajar'] = df_fatia['DISP_VIAJAR'].apply(lambda x: 1 if x == 'S' else 0)df_fatia['Dormir_local'] = Nonedf_fatia['Dormir_local'] = df_fatia['DISP_DORMIR_EMP'].apply(lambda x: 1 if x == 'S' else 0)df_fatia['Ausentar_Domic'] = Nonedf_fatia['Ausentar_Domic'] = df_fatia['DISP_AUSENTAR_DOMIC'].apply(lambda x: 1 if x == 'S' else 0)| ESCOLARIDADE | Nivel_esc | Quantidade |
|---|---|---|
| Médio Completo | 2 | 72167 |
| Fundamental Completo | 1 | 15326 |
| Médio Incompleto | 2 | 14627 |
| Superior Completo | 3 | 10908 |
| Superior Incompleto | 3 | 8852 |
| Fundamental Incompleto | 1 | 4142 |
| Nenhum | 0 | 1646 |
| Analfabeto | 0 | 499 |
| Especialização | 3 | 466 |
| Mestrado | 3 | 101 |
| Doutorado | 3 | 14 |
3. Enriquecimento de Base
3.1 Coluna Região:
Categorização das cidades em regiões municipais no Estado de Santa Catarina, Conforme o seguinte link.
Segue o dicionário de dados com a coluna região, criada:reg = {'ararangua':'sul','armazem':'sul','balneario arroio do silva':'sul','balneario gaivota':'sul','balneario rincao':'sul','braco do norte':'sul','capivari de baixo':'sul','cocal do sul':'sul','criciuma':'sul','ermo':'sul','forquilhinha':'sul','garopaba':'sul','grao para':'sul','gravatal':'sul','icara':'sul','imarui':'sul','imbituba':'sul','jacinto machado':'sul','jaguaruna':'sul','laguna':'sul','lauro muller':'sul','maracaja':'sul','meleiro':'sul','morro da fumaca':'sul','morro grande':'sul','nova veneza':'sul','orleans':'sul','passo de torres':'sul','pedras grandes':'sul','pescaria brava':'sul','praia grande':'sul','rio fortuna':'sul','sangao':'sul','santa rosa de lima':'sul','santa rosa do sul':'sul','sao joao do sul':'sul','sao ludgero':'sul','sao martinho':'sul','sideropolis':'sul','sombrio':'sul','timbe do sul':'sul','treviso':'sul','treze de maio':'sul','tubarao':'sul','turvo':'sul','urussanga':'sul','aguas mornas':'grande florianópolis','alfredo wagner':'grande florianópolis','angelina':'grande florianópolis','anitapolis':'grande florianópolis','antonio carlos':'grande florianópolis','biguacu':'grande florianópolis','canelinha':'grande florianópolis','florianopolis':'grande florianópolis','governador celso ramos':'grande florianópolis','leoberto leal':'grande florianópolis','major gercino':'grande florianópolis','nova trento':'grande florianópolis','palhoca':'grande florianópolis','paulo lopes':'grande florianópolis','rancho queimado':'grande florianópolis','santo amaro da imperatriz':'grande florianópolis','sao bonifacio':'grande florianópolis','sao joao batista':'grande florianopolis','sao jose':'grande florianópolis','sao pedro de alcantara':'grande florianópolis','tijucas':'grande florianópolis','araquari':'norte','balneario barra do sul':'norte','bela vista do toldo':'norte','campo alegre':'norte','canoinhas':'norte','corupa':'norte','garuva':'norte','guaramirim':'norte','irineppolis':'norte','itaiopolis':'norte','itapoa':'norte','jaragua do sul':'norte','joinville':'norte','mafra':'norte','major vieira':'norte','massaranduba':'norte','monte castelo':'norte','papanduva':'norte','porto uniao':'norte','rio negrinho':'norte','santa terezinha':'norte','sao bento do sul':'norte','sao francisco do sul':'norte','schroeder':'norte','timbo grande':'norte','tres barras':'norte','abelardo luz': 'oeste','agua doce': 'oeste','aguas de chapeco': 'oeste','aguas frias': 'oeste','alto bela vista': 'oeste','anchieta': 'oeste','arabuta': 'oeste','arroio trinta': 'oeste','arvoredo': 'oeste','bandeirante': 'oeste','barra bonita': 'oeste','belmonte': 'oeste','bom jesus': 'oeste','bom jesus do oeste': 'oeste','cacador': 'oeste','caibi': 'oeste','calmon': 'oeste','campo ere': 'oeste','capinzal': 'oeste','catanduvas': 'oeste','caxambu do sul': 'oeste','chapeco': 'oeste','concordia': 'oeste','cordilheira alta': 'oeste','coronel freitas': 'oeste','coronel martins': 'oeste','cunha pora': 'oeste','cunhatai': 'oeste','descanso': 'oeste','dionisio cerqueira': 'oeste','entre rios': 'oeste','erval velho': 'oeste','faxinal dos guedes': 'oeste','flor do sertao': 'oeste','formosa do sul': 'oeste','fraiburgo': 'oeste','galvao': 'oeste','guaraciaba': 'oeste','guaruja do sul': 'oeste','guatambu': 'oeste',"herval d oeste": 'oeste','ibiam': 'oeste','ibicare': 'oeste','iomere': 'oeste','ipira': 'oeste','ipora do oeste': 'oeste','ipuacu': 'oeste','ipumirim': 'oeste','iraceminha': 'oeste','irani': 'oeste','irati': 'oeste','ita': 'oeste','itapiranga': 'oeste','jabora': 'oeste','jardinopolis': 'oeste','joacaba': 'oeste','jupia': 'oeste','lacerdopolis': 'oeste','lajeado grande': 'oeste','lebon regis': 'oeste','lindoia do sul': 'oeste','luzerna': 'oeste','macieira': 'oeste','maravilha': 'oeste','marema': 'oeste','matos costa': 'oeste','modelo': 'oeste','mondai': 'oeste','nova erechim': 'oeste','nova itaberaba': 'oeste','novo horizonte': 'oeste','ouro': 'oeste','ouro verde': 'oeste','paial': 'oeste','palma sola': 'oeste','palmitos': 'oeste','paraiso': 'oeste','passos maia': 'oeste','peritiba': 'oeste','pinhalzinho': 'oeste','pinheiro preto': 'oeste','piratuba': 'oeste','planalto alegre': 'oeste','ponte serrada': 'oeste','presidente castelo branco': 'oeste','princesa': 'oeste','quilombo': 'oeste','rio das antas': 'oeste','riqueza': 'oeste','romelandia': 'oeste','saltinho': 'oeste','salto veloso': 'oeste','santa helena': 'oeste','santa terezinha do progresso': 'oeste','santiago do sul': 'oeste','sao bernardino': 'oeste','sao carlos': 'oeste','sao domingos': 'oeste','sao joao do oeste': 'oeste','sao jose do cedro': 'oeste','sao lourenco do oeste': 'oeste','sao miguel da boa vista': 'oeste','sao miguel do oeste': 'oeste','saudades': 'oeste','seara': 'oeste','serra alta': 'oeste','sul brasil': 'oeste','tangara': 'oeste','tigrinhos': 'oeste','treze tilias': 'oeste','tunapolis': 'oeste','uniao do oeste': 'oeste','vargeao': 'oeste','vargem bonita': 'oeste','videira': 'oeste','xanxere': 'oeste','xavantina': 'oeste','xaxim': 'oeste','abdon batista' : 'serrtana','anita garibaldi' : 'serrtana','bocaina do sul' : 'serrtana','bom jardim da serra' : 'serrtana','bom retiro' : 'serrtana','brunopolis' : 'serrtana','campo belo do sul' : 'serrtana','campos novos' : 'serrtana','capao alto' : 'serrtana','celso ramos' : 'serrtana','cerro negro' : 'serrtana','correia pinto' : 'serrtana','curitibanos' : 'serrtana','frei rogerio' : 'serrtana','lages' : 'serrtana','monte carlo' : 'serrtana','otacilio costa' : 'serrtana','painel' : 'serrtana','palmeira' : 'serrtana','ponte alta' : 'serrtana','ponte alta do norte' : 'serrtana','rio rufino' : 'serrtana','santa cecilia' : 'serrtana','sao cristovao do sul' : 'serrtana','sao joaquim' : 'serrtana','sao jose do cerrito' : 'serrtana','urubici' : 'serrtana','urupema' : 'serrtana','vargem' : 'serrtana','zortea' : 'serrtana','agrolandia' : 'vale do iajaí','agronomica' : 'vale do iajaí','apiuna' : 'vale do iajaí','ascurra' : 'vale do iajaí','atalanta' : 'vale do iajaí','aurora' : 'vale do iajaí','balneario camboriu' : 'vale do iajaí','balneario picarras' : 'vale do iajaí','barra velha' : 'vale do iajaí','benedito novo' : 'vale do iajaí','blumenau' : 'vale do iajaí','bombinhas' : 'vale do iajaí','botuvera' : 'vale do iajaí','braco do trombudo' : 'vale do iajaí','brusque' : 'vale do iajaí','camboriu': 'vale do iajaí','chapadao do lageado' : 'vale do iajaí','dona emma' : 'vale do iajaí','doutor pedrinho' : 'vale do iajaí','gaspar' : 'vale do iajaí','guabiruba' : 'vale do iajaí','ibirama' : 'vale do iajaí','ilhota' : 'vale do iajaí','imbuia' : 'vale do iajaí','indaial' : 'vale do iajaí','itajai' : 'vale do iajaí','itapema' : 'vale do iajaí','ituporanga' : 'vale do iajaí','jose boiteux' : 'vale do iajaí','laurentino' : 'vale do iajaí','lontras' : 'vale do iajaí','luiz alves' : 'vale do iajaí','mirim doce' : 'vale do iajaí','navegantes' : 'vale do iajaí','penha' : 'vale do iajaí','petrolandia' : 'vale do iajaí','pomerode' : 'vale do iajaí','porto belo' : 'vale do iajaí','pouso redondo' : 'vale do iajaí','presidente getulio' : 'vale do iajaí','presidente nereu' : 'vale do iajaí','rio do campo' : 'vale do iajaí','rio do oeste' : 'vale do iajaí','rio do sul' : 'vale do iajaí','rio dos cedros' : 'vale do iajaí','rodeio' : 'vale do iajaí','salete' : 'vale do iajaí','sao joao do itaperiu' : 'vale do iajaí','taio' : 'vale do iajaí','timbo' : 'vale do iajaí','trombudo central' : 'vale do iajaí','vidal ramos' : 'vale do iajaí','vitor meireles' : 'vale do iajaí','witmarsum' : 'vale do iajaí','irineopolis':'Norte', 'presidente castello branco':'Oeste'
}df_fatia['Regiao'] = df_fatia['NOME_MUNICIPIO']df_fatia['Regiao'] = df_fatia['Regiao'].str.lower()df_fatia['Regiao'] = df_fatia['Regiao'].map(reg)df_fatia['Regiao'] = df_fatia['Regiao'].map({'norte':'Norte', 'sul':'Sul', 'grande florianópolis':'Grande Florianópolis', 'oeste':'Oeste', 'serrtana': 'Serrana', 'vale do iajaí': 'Vale do Iajaí'})df_fatia['Regiao'][df_fatia['NOME_MUNICIPIO'] == 'IRINEOPOLIS'] = 'Norte'df_fatia['Regiao'][df_fatia['NOME_MUNICIPIO'] == 'SAO JOAO BATISTA'] = 'Grande Florianópolis'df_fatia['Regiao'][df_fatia['NOME_MUNICIPIO'] == 'PRESIDENTE CASTELLO BRANCO'] = 'Oeste'df_fatia['Regiao'].value_counts())/df_fatia.shape[0]*100).round(2)| Regiao | Quantidade de Pessoas (Perc. %) |
|---|---|
| Vale do Iajaí | 27.24 |
| Norte | 22.25 |
| Grande Florianópolis | 18.36 |
| Sul | 13.87 |
| Oeste | 13.76 |
| Serrana | 4.52 |
3.2 PIB por Cidade:
Para o enriquecimento da base foi acrescentado a variável PIB por cidade, conforme o link (Wikipédia). Para coletar tais informações, houve a necessidade de fazer uma limpeza dos dados, devido não estar em formação numérica.
print(pib.head())| Município | PIB em 2018 | |
|---|---|---|
| 0 | Joinville | 30 785 682 |
| 1 | Itajaí | 25 413 431 |
| 2 | Florianópolis | 21 059 561 |
| 3 | Blumenau | 16 958 783 |
| 4 | São José | 10 607 482 |
for i in range(pib.shape[0]):
unidecode.unidecode(pib.loc[i,'PIB em 2018'])Removendo os ponto e as virgulas.
pib['pib'] = pib['PIB em 2018'].str.replace(".","")
pib['pib'] = pib['pib'].str.replace(",","")Removendo os unidecode.
pib['pib'] = pib['pib'].str.replace(u'\xa0', '')Removendo os espaços vazios
pib['pib'] = pib['pib'].str.replace(" ","")Criando a coluna Percentual.
pib["percentual"] = pib['pib'].astype(int) / pib['pib'].astype(int).sum()Removendo a coluna PIB em 2018.
pib.drop(columns=['PIB em 2018'], inplace = True)Criando a coluna Região, com os caracteris todos em minúsculo.
pib['Regiao'] = pib['Município'].str.lower()Manipulando os nomes de todas as cidade do estado de Santa Catarina.
pib['Regiao'] = pib['Regiao'].map({
'joinville' : 'joinville',
'itajaí' : 'itajai',
'florianópolis' : 'florianopolis',
'blumenau' : 'blumenau',
'são josé' : 'sao jose',
'chapecó' : 'chapeco',
'jaraguá do sul' : 'jaragua do sul',
'criciúma' : 'criciuma',
'brusque' : 'brusque',
'balneário camboriú' : 'balneario camboriu',
'palhoça' : 'palhoca',
...
'coronel martins' : 'coronel martins',
'matos costa' : 'matos costa',
'flor do sertão' : 'flor do sertao',
'cunhataí' : 'cunhatai',
'barra bonita' : 'barra bonita',
'irati' : 'irati',
'paial' : 'paial',
'são miguel da boa vista' : 'sao miguel da boa vista',
'jardinópolis' : 'jardinopolis',
'santiago do sul' : 'santiago do sul'})pib['Cidade'] = pib['Regiao']pib.head()| Município | pib | percentual | Cidade | Regiao | |
|---|---|---|---|---|---|
| 0 | Joinville | 30785682.0 | 0.064574 | joinville | Norte |
| 1 | Itajaí | 25413431.0 | 0.053306 | itajai | Vale do Iajaí |
| 2 | Florianópolis | 21059561.0 | 0.044173 | florianopolis | Grande Florianópolis |
| 3 | Blumenau | 16958783.0 | 0.035572 | blumenau | Vale do Iajaí |
| 4 | São José | 10607482.0 | 0.022250 | sao jose | Grande Florianópolis |
Unindo os conjuntos de dados (merge) PIB e df_fatia.
pib_merge = pib[['Cidade','pib','percentual']]df_fatia['Cidade'] = df_fatia['NOME_MUNICIPIO'].str.lower()df_merge_pib = df_fatia.merge(pib_merge,
on = 'Cidade',how='left')pib.drop(columns =['Regiao'], inplace = True)pib = pib.merge(df_fatia[['Cidade','Regiao']].drop_duplicates(),
on = 'Cidade',
how='left')pib['pib'] = pib['pib'].astype(float)pib_group = pib.groupby('Regiao')['pib','percentual'].sum()pib_group['percentual'] = (pib_group['percentual']*100).round(2)pib_group.rename(columns = {'percentual':'Per. (%)'}, inplace = True)pib_group| pib | Per. (%) | |
|---|---|---|
| Regiao | ||
| Grande Florianópolis | 44616635.0 | 9.36 |
| Norte | 65983990.0 | 13.84 |
| Oeste | 46454513.0 | 9.74 |
| Serrana | 12623611.0 | 2.65 |
| Sul | 31170034.0 | 6.54 |
| Vale do Iajaí | 272782471.0 | 57.22 |
Salvando os conjuntos de dados.
pib.to_csv('pib_cidade_limpo.csv', index = False)pib_group.to_csv('pib_por_regiao.csv', index = False)df_merge_pib.to_csv('df_merge_pib.csv', index = False)3.3 PIB Médio por Cidade:
Criando um PIB médio por cidade
pib_group.reset_index(inplace = True)Criar uma lista com a quantidade de cidade por região:
lista = [len(pib[pib['Regiao'] == 'Grande Florianópolis']['Cidade'].unique()), len(pib[pib['Regiao'] == 'Norte']['Cidade'].unique()), len(pib[pib['Regiao'] == 'Oeste']['Cidade'].unique()), len(pib[pib['Regiao'] == 'Serrana']['Cidade'].unique()), len(pib[pib['Regiao'] == 'Sul']['Cidade'].unique()), len(pib[pib['Regiao'] == 'Vale do Iajaí']['Cidade'].unique())]cidade = pd.DataFrame({'Regiao': pib_group.Regiao, "n_cidade":lista})cidade| Regiao | n_cidade | |
|---|---|---|
| 0 | Grande Florianópolis | 20 |
| 1 | Norte | 26 |
| 2 | Oeste | 116 |
| 3 | Serrana | 29 |
| 4 | Sul | 44 |
| 5 | Vale do Iajaí | 53 |
pib_regiao = pib_group.merge(cidade)pib_regiao| Regiao | pib | Per. (%) | n_cidade | Pib_medio_cidade | |
|---|---|---|---|---|---|
| 0 | Grande Florianópolis | 44616635.0 | 9.42 | 20 | 2230831.75 |
| 1 | Norte | 65983990.0 | 13.93 | 26 | 2537845.77 |
| 2 | Oeste | 46454513.0 | 9.80 | 116 | 400469.94 |
| 3 | Serrana | 12623611.0 | 2.67 | 29 | 435296.93 |
| 4 | Sul | 31170034.0 | 6.58 | 44 | 708409.86 |
| 5 | Vale do Iajaí | 272782471.0 | 57.59 | 53 | 5146839.08 |
pib_regiao['Pib_medio_cidade'] = (pib_regiao['pib'] / pib_regiao['n_cidade']).round(2)
pib_regiao['Per. (%)'] = (pib_regiao['Per. (%)']/pib_regiao['Per. (%)'].sum()*100).round(2)pib_regiao.sort_values(by = ['Per. (%)'], ascending = False)| Regiao | pib | Per. (%) | n_cidade | Pib_medio_cidade | |
|---|---|---|---|---|---|
| 5 | Vale do Iajaí | 272782471 | 57.59 | 53 | 5146839.08 |
| 1 | Norte | 65983990 | 13.93 | 26 | 2537845.77 |
| 2 | Oeste | 46454513 | 9.80 | 116 | 400469.94 |
| 0 | Grande Florianópolis | 44616635 | 9.42 | 20 | 2230831.75 |
| 4 | Sul | 31170034 | 6.58 | 44 | 708409.86 |
| 3 | Serrana | 12623611 | 2.67 | 29 | 435296.93 |
4. Coluna Prestação
4.1 Estágio e Horário de Trabalho:
A coluna Pretenção possuem diversas informações, que teremos que organizar para conseguir obter os dados de forma separada.
prest = df_merge_pib.copy() prest.loc[0,'PRETENSOES']# '724405-CALDEIREIRO (CHAPAS DE COBRE)(N,6,0,Indiferente)|724435-Funileiro industrial(N,99,0,Indiferente)|731105-MONTADOR DE EQUIPAMENTOS ELETRONICOS (APARELHOS MEDICOS)(N,3,0,Comercial)784205-Auxiliar de linha de produção(N,0,0,Indiferente)'
Essa coluna possue pretenção de emprego, estágio, trabalho informal, trabalho formal e horário pretendido para trabalhar. É possível obter todos este dados de forma separada.
padrao = re.compile('[N-S]?(,)[0-9]?[0-9]?[0-9]?[0-9]?(,)[0-9]?[0-9]?[0-9]?[0-9]?,(Indiferente)?(Comercial)?(Manhã)?(Tarde)?(Noite)?(Madrugada)?(Manhã/Tarde)?(Manhã/Noite)?(Manhã/Madrugada)?(Manhã/Tarde/Noite)?(Manhã/Tarde/Madrugada)?(Manhã/Noite/Madrugada)?(Manhã/Tarde/Noite/Madrugada)?(Tarde/Noite)?(Tarde/Madrugada)?(Tarde/Noite/Madrugada)?(Noite/Madrugada)?')prest['info'] = Noneprest.dropna(subset =['PRETENSOES'], inplace = True)prest.reset_index(inplace = True)prest.drop(columns = ['index'], inplace = True)inf = []for i in range(prest.shape[0]): acrescenta = padrao.search(prest.loc[i,'PRETENSOES']).group() inf.append(acrescenta)Segue amostra dos dados higienizados:
['N,6,0,Indiferente','N,166,0,Indiferente','N,0,0,Indiferente','N,55,0,Indiferente','N,3,0,Indiferente']
prest['info'] = infestagio, Experiencia_Formal, Experiencia_informal, Horario = [], [], [], []for i in range(prest.shape[0]): inf = prest.loc[i,'info'].split(sep = ',') estagio.append(inf[0]) Experiencia_Formal.append(inf[1]) Experiencia_informal.append(inf[2]) Horario.append(inf[3])prest['Estagio'] = estagioprest['Experiencia_Formal'] = Experiencia_Formalprest['Experiencia_informal'] = Experiencia_informalprest['Horario'] = Horarioprest[['Nivel_esc','Regiao','Cidade','pib','percentual','info','Estagio','Experiencia_Formal','Experiencia_informal','Horario']].head()
| Nivel_esc | Regiao | Cidade | pib | percentual | info | Estagio | Experiencia_Formal | Experiencia_informal | Horario | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | Norte | joinville | 30785682 | 0.064574 | N,6,0,Indiferente | N | 6 | 0 | Indiferente |
| 1 | 1 | Norte | papanduva | 543649 | 0.001140 | N,166,0,Indiferente | N | 166 | 0 | Indiferente |
| 2 | 3 | Grande Florianópolis | palhoca | 5489675 | 0.011515 | N,0,0,Indiferente | N | 0 | 0 | Indiferente |
| 3 | 2 | Sul | capivari de baixo | 429616 | 0.000901 | N,55,0,Indiferente | N | 55 | 0 | Indiferente |
| 4 | 2 | Vale do Iajaí | navegantes | 3820583 | 0.008014 | N,3,0,Indiferente | N | 3 | 0 | Indiferente |
4.2 Cargo Pretendido:
Coletamos separadamento as pretenções solicitadas por trabalhados. Com o CBO identificado, consegui enriquecer os dados com novas informações. atrás do conjunto de dados do site: salario.com.br.
df_CBO.head()| CBO | Cargo | Carga Horária | Piso Salarial | Média Salarial | Salário Mediana | Teto Salarial | Salário Hora | |
|---|---|---|---|---|---|---|---|---|
| 0 | 612510 | Abacaxicultor | 41 | 1.313,38 | 1.439,02 | 1.134,65 | 2.174,69 | 7,09 |
| 1 | 263105 | Abade | 40 | 2.983,98 | 3.269,43 | 2.197,00 | 4.940,87 | 16,54 |
| 2 | 263105 | Abadessa | 40 | 2.983,98 | 3.269,43 | 2.197,00 | 4.940,87 | 16,54 |
| 3 | 622020 | Abanador na Agricultura | 44 | 1.220,07 | 1.336,78 | 1.232,44 | 2.020,18 | 6,1 |
| 4 | 862120 | Abastecedor de Caldeira | 43 | 1.619,68 | 1.774,62 | 1.636,76 | 2.681,86 | 8,24 |
# Ordenando o arquivo CBOdf_CBO.sort_values("CBO", inplace = True) print(df_CBO.shape)# Elimando os registros duplicados em CBO, deixando apenas o primeiro de cada chavedf_CBO.drop_duplicates(subset ="CBO",keep = 'first', inplace = True)df_CBO = df_CBO.reset_index(drop=True)print(df_CBO.shape)# (9334, 8)
# (2334, 8)
# Transformando as strings de Média Salarial e Salário Mediana em numérico (float)def transforma_float(x): return float(x.replace('.','').replace(',','.'))df_CBO['CBO'] = df_CBO['CBO'].map(str)cbo_colunas = df_CBO.columns for i in range(3,8): df_CBO[cbo_colunas[i]] = df_CBO[cbo_colunas[i]].apply(lambda x: transforma_float(x))df_CBO['CBO'].head()0 1111201 1112202 1113203 1114054 111410Name: CBO, dtype: object
padrao = re.compile('[0-9]{6}')lista = []def get_cbo(row): if type(row) == float and np.isnan(row): return [] return re.findall(padrao, row)lista.append(prest['PRETENSOES'].apply(get_cbo))count = []for i in range(len(lista[0])): count.append(len(lista[0][i]))cbo_cid , cidadao = [], []for num in range(len(lista[0])): for i in range(count[num]): cbo_cid.append(lista[0][num][i]) cidadao.append(num)df_cbo_cidadao = pd.DataFrame({'cbo': cbo_cid, 'id_cidadao' : cidadao})df_cbo_cidadao = df_cbo_cidadao.merge(df_CBO, left_on = 'cbo', right_on = 'CBO')df_cbo_cidadao.drop(columns =['CBO'], inplace = True)Vamos observar o a terceira observação, ou cidadao. Ele teve 04 pretenção de emprego.
df_cbo_cidadao[df_cbo_cidadao['id_cidadao'] == 3]| cbo | id_cidadao | Cargo | Carga Horária | Piso Salarial | Média Salarial | Salário Mediana | Teto Salarial | Salário Hora | |
|---|---|---|---|---|---|---|---|---|---|
| 176803 | 521110 | 3 | Consultor de Vendas | 43 | 1240.57 | 1359.25 | 1294.34 | 2054.14 | 6.27 |
| 176804 | 521110 | 3 | Operador de Vendas (lojas) | 43 | 1240.57 | 1359.25 | 1294.34 | 2054.14 | 6.27 |
| 176805 | 521110 | 3 | Vendedor - no Comércio de Mercadorias | 43 | 1240.57 | 1359.25 | 1294.34 | 2054.14 | 6.27 |
| 176806 | 521110 | 3 | Vendedor de Comercio Varejista | 43 | 1240.57 | 1359.25 | 1294.34 | 2054.14 | 6.27 |
| 176807 | 521110 | 3 | Vendedor Interno | 43 | 1240.57 | 1359.25 | 1294.34 | 2054.14 | 6.27 |
df_cbo_cidadao.head()| cbo | id_cidadao | Cargo | Carga Horária | Piso Salarial | Média Salarial | Salário Mediana | Teto Salarial | Salário Hora | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 724405 | 0 | Caldeireiro (Chapas de Cobre) | 44 | 2224.17 | 2436.94 | 2285.8 | 3682.77 | 11.11 |
| 1 | 724405 | 657 | Caldeireiro (Chapas de Cobre) | 44 | 2224.17 | 2436.94 | 2285.8 | 3682.77 | 11.11 |
| 2 | 724405 | 1419 | Caldeireiro (Chapas de Cobre) | 44 | 2224.17 | 2436.94 | 2285.8 | 3682.77 | 11.11 |
| 3 | 724405 | 1943 | Caldeireiro (Chapas de Cobre) | 44 | 2224.17 | 2436.94 | 2285.8 | 3682.77 | 11.11 |
| 4 | 724405 | 2579 | Caldeireiro (Chapas de Cobre) | 44 | 2224.17 | 2436.94 | 2285.8 | 3682.77 | 11.11 |
df_cbo_cidadao.groupby('id_cidadao')[['Piso Salarial','Teto Salarial']].agg(['min','median','mean','max','std']).head()| Piso Salarial | Teto Salarial | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| min | median | mean | max | std | min | median | mean | max | std | |
| id_cidadao | ||||||||||
| 0 | 1280.47 | 1688.845 | 1599.946875 | 2224.17 | 317.058355 | 2120.20 | 2796.385 | 2649.187500 | 3682.77 | 524.982724 |
| 1 | 1240.57 | 1240.570 | 2303.770000 | 3632.77 | 1260.800103 | 2054.14 | 2054.140 | 3814.584444 | 6015.14 | 2087.630302 |
| 2 | 1192.69 | 1240.570 | 1399.186000 | 2450.67 | 401.193490 | 1974.85 | 2054.140 | 2316.770000 | 4057.81 | 664.297188 |
| 3 | 1240.57 | 1240.570 | 1240.570000 | 1240.57 | 0.000000 | 2054.14 | 2054.140 | 2054.140000 | 2054.14 | 0.000000 |
| 5 | 1132.92 | 1227.410 | 1222.081364 | 1292.58 | 54.245144 | 1875.89 | 2032.345 | 2023.522273 | 2140.26 | 89.817688 |
Análise Exploratória
Visualização detalhada do conjunto de dados, transformando - os, em informações ricas, para obtenção de insights de negócios.