 Análise Exploratória dos Dados
Análise Exploratória dos Dados

A Análise Exploratória de Dados (EDA - Exploratory Data Analysis) é o processo de investigar os dados com
estatísticas e representações gráficas para melhor compreendê-los. Utilizando técnicas para tratar valores ausentes que possam existir na
base de dados, padronizar variáveis que não estão na mesma escala, identificar correlações entre elas e gerar estatísticas
descritivas. A análise exploratória pode variar conforme o tipo de dados.
Na análise estatística clássica, por exemplo, há necessidade de testar hipóteses já existentes sobre o problema.
Mas, em projetos de Aprendizado de Máquina raramente é conhecemos o problema por completo e hipóteses sobre ele.
Como a EDA possui uma abordagem mais holística em comparação com a análise clássica, nenhuma suposição antecipada é
necessária, não há perda de informação e é possível obter mais insights porque todos os dados brutos estão disponíveis
para serem analisados para então começar a criar hipóteses.
1. Carregando os Dados
Tópico
1.1 Carregando Bibliotecas e Carregando os dados:
Conforme a etapa anterior, de pré-processamento dos dados,
esta etapa se inicia com o conjunto de dados transformados.
Script Python
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport matplotlib as mimport seaborn as sns%matplotlib inlinefrom scipy.stats import ranksumsimport glob # busca os arquivos em um caminho (path)import osimport refrom sklearn.cluster import KMeansfrom sklearn.preprocessing import StandardScalerfrom biokit.viz import corrplotimport seaborn as snsfrom sklearn.model_selection import train_test_splitimport statsmodels.api as smfrom matplotlib.colors import ListedColormapfrom wordcloud import WordCloud, STOPWORDS, ImageColorGeneratorfrom PIL import Imageimport pygal
df_cbo_cidadao = pd.read_csv('site/github/Dados/df_cbo_cidadao.csv')df_prest = pd.read_csv('site/github/Dados/df_prest.csv')
%reload_ext watermark
%watermark -a "Data Scientist: Data Tree" --iversions
Author: Data Scientist: Data Treere : 2.2.1biokit : 0.5.0statsmodels: 0.12.2PIL : 8.3.2numpy : 1.21.2matplotlib : 3.4.3seaborn : 0.11.2pandas : 1.3.3
df_cbo_cidadao.head(3)
|
cbo |
id_cidadao |
Cargo |
Carga Horária |
Piso Salarial |
Média Salarial |
Salário Mediana |
Teto Salarial |
Salário Hora |
| 0 |
724405 |
0 |
Caldeireiro (Chapas de Cobre) |
44 |
2224.17 |
2436.94 |
2285.8 |
3682.77 |
11.11 |
| 1 |
724405 |
657 |
Caldeireiro (Chapas de Cobre) |
44 |
2224.17 |
2436.94 |
2285.8 |
3682.77 |
11.11 |
| 2 |
724405 |
1419 |
Caldeireiro (Chapas de Cobre) |
44 |
2224.17 |
2436.94 |
2285.8 |
3682.77 |
11.11 |
Uma análise estatística das variáveis:
df_cbo_cidadao.describe()
|
cbo |
id_cidadao |
Carga Horária |
Piso Salarial |
Média Salarial |
Salário Mediana |
Teto Salarial |
Salário Hora |
| count |
2.368206e+06 |
2.368206e+06 |
2.368206e+06 |
2.368206e+06 |
2.368206e+06 |
2.368206e+06 |
2.368206e+06 |
2368206.00 |
| mean |
5.662109e+05 |
5.538242e+04 |
4.318341e+01 |
1.520697e+03 |
1.666113e+03 |
1.499674e+03 |
2.517880e+03 |
inf |
| std |
1.923784e+05 |
3.209005e+04 |
1.428161e+00 |
6.887980e+02 |
7.547279e+02 |
4.853845e+02 |
1.140566e+03 |
NaN |
| min |
1.112200e+05 |
0.000000e+00 |
0.000000e+00 |
1.100000e+03 |
1.100000e+03 |
1.045000e+03 |
1.662350e+03 |
5.00 |
| 25% |
4.211250e+05 |
2.754900e+04 |
4.300000e+01 |
1.187960e+03 |
1.301610e+03 |
1.264750e+03 |
1.967030e+03 |
6.08 |
| 50% |
5.199350e+05 |
5.533800e+04 |
4.300000e+01 |
1.280470e+03 |
1.402960e+03 |
1.376290e+03 |
2.120200e+03 |
6.45 |
| 75% |
7.711050e+05 |
8.308100e+04 |
4.400000e+01 |
1.589990e+03 |
1.742100e+03 |
1.538310e+03 |
2.632710e+03 |
8.01 |
| max |
9.922250e+05 |
1.110880e+05 |
4.400000e+01 |
2.023275e+04 |
2.216828e+04 |
2.000000e+04 |
3.350137e+04 |
inf |
df_prest.head(3)
|
NACIONALIDADE |
DEFICIENCIAS |
BAIRRO |
CEP |
CODIGO_MUNICIPIO_IBGE |
NOME_MUNICIPIO |
UF |
ESCOLARIDADE |
ESTUDANTE |
CURSOS_PROFISSIONALIZANTES |
GRADUACOES |
POS_GRADUACOES |
IDIOMAS |
HABILITACAO |
VEICULOS |
DISP_VIAJAR |
DISP_DORMIR_EMP |
DISP_AUSENTAR_DOMIC |
PRETENSOES |
MUNICIPIOS_INTERESSE |
Estudante |
Veiculo |
Viajar |
Dormir_local |
Ausentar_Domic |
Nivel_esc |
Regiao |
Cidade |
pib |
percentual |
info |
Estagio |
Experiencia_Formal |
Experiencia_informal |
Horario |
| 0 |
BRASILEIRA |
NaN |
AVENTUREIRO |
89225560.0 |
420910 |
JOINVILLE |
SC |
Médio Completo |
N |
NaN |
NaN |
NaN |
NaN |
Nenhum |
N |
N |
N |
N |
724405-CALDEIREIRO (CHAPAS DE COBRE)(N,6,0,Indiferente)|724435-Funileiro industrial(N,99,0,Indiferente)|731105-MONTADOR DE EQUIPAMENTOS ELETRONICOS (APARELHOS MEDICOS)(N,3,0,Comercial)|784205-Auxiliar de linha de produção(N,0,0,Indiferente) |
NaN |
0 |
0 |
0 |
0 |
0 |
2 |
Norte |
joinville |
30785682.0 |
0.064574 |
N,6,0,Indiferente |
N |
6 |
0 |
Indiferente |
| 1 |
BRASILEIRA |
NaN |
CENTRO |
89370000.0 |
421220 |
PAPANDUVA |
SC |
Fundamental Completo |
N |
NaN |
NaN |
NaN |
NaN |
Nenhum |
N |
N |
N |
N |
142305-Gerente comercial(N,166,0,Indiferente)|521110-Vendedor - no comercio de mercadorias(N,0,0,Comercial) |
NaN |
0 |
0 |
0 |
0 |
0 |
1 |
Norte |
papanduva |
543649.0 |
0.001140 |
N,166,0,Indiferente |
N |
166 |
0 |
Indiferente |
| 2 |
BRASILEIRA |
NaN |
BARRA DO ARIRIU |
88134597.0 |
421190 |
PALHOCA |
SC |
Superior Incompleto |
N |
NaN |
GESTAO DE MARKETING E VENDAS |
NaN |
Espanhol Intermediário |
Nenhum |
S |
N |
S |
S |
252525-Analista de crédito (instituições financeiras)(N,0,0,Indiferente)|421310-Assistente de cobrança(N,0,0,Indiferente)|510310-Supervisor de segurança (vigilância)(N,0,0,Indiferente)|517425-Fiscal de loja(N,30,0,Indiferente)|521110-Vendedor interno(N,56,0,Indiferente)|521115-Promotor de vendas(N,0,0,Indiferente) |
NaN |
0 |
1 |
0 |
1 |
1 |
3 |
Grande Florianópolis |
palhoca |
5489675.0 |
0.011515 |
N,0,0,Indiferente |
N |
0 |
0 |
Indiferente |
2. Explorando as Variáveis
2.1. Quantidade de Candidatos por Nacionalidade
Tópico
Script Python
df_nacionalidade = pd.DataFrame(df_empregos['NACIONALIDADE'].value_counts())df_nacionalidade.reset_index(inplace=True)df_nacionalidade = df_nacionalidade.rename(columns = {'index':'Nacionalidade', 'NACIONALIDADE':'Candidatos'})df_nacionalidade['Percentual'] = df_nacionalidade['Candidatos'] / df_nacionalidade['Candidatos'].sum()df_nacionalidade = df_nacionalidade.style.set_table_styles(contorno)df_nacionalidade.format("{:7.2%}", subset=["Percentual"])print("\n {}{:^55}{}".format(color.BOLD, 'Quantidade de Candidatos por Nacionalidade', color.END))display(df_nacionalidade)
| |
Nacionalidade |
Candidatos |
Percentual |
| 0 |
BRASILEIRA |
107777 |
97.66% |
| 1 |
ESTRANGEIRA |
2402 |
2.18% |
| 2 |
NATURALIZADO BRASILEIRO |
103 |
0.09% |
| 3 |
BRASILEIRO NASCIDO NO EXTERIOR |
72 |
0.07% |
2.2. Quantidade de Candidatos por Município
Tópico
Script Python
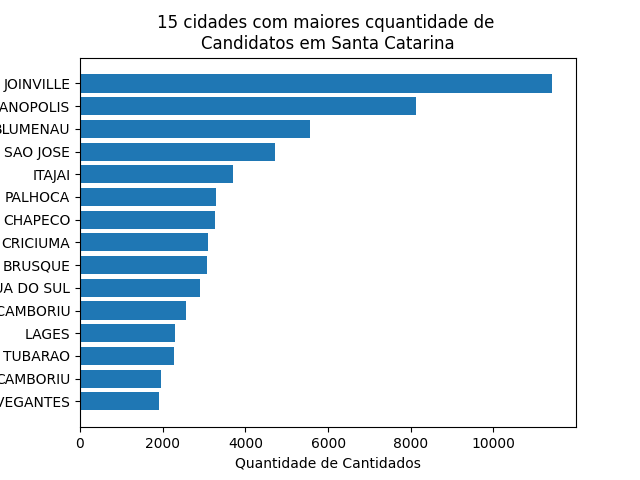
df_municipio = pd.DataFrame(df_empregos['NOME_MUNICIPIO'].value_counts())df_municipio.reset_index(inplace=True)df_municipio = df_municipio.rename(columns ={'index':'Nacionalidade', 'NOME_MUNICIPIO':'Qtd.Candidatos'})df_municipio['Percentual'] = df_municipio['Qtd.Candidatos'] / df_municipio['Qtd.Candidatos'].sum()df_municipio['Acumulado'] = df_municipio['Percentual'].cumsum()df_municipio = df_municipio.head(9)df_municipio = df_municipio.style.set_table_styles(contorno)df_municipio.format("{:7.2%}", subset=["Percentual", "Acumulado"])display(df_municipio)
| |
Nacionalidade |
Qtd.Candidatos |
Percentual |
Acumulado |
| 0 |
JOINVILLE |
11425 |
10.35% |
10.35% |
| 1 |
FLORIANOPOLIS |
8126 |
7.36% |
17.72% |
| 2 |
BLUMENAU |
5555 |
5.03% |
22.75% |
| 3 |
SAO JOSE |
4715 |
4.27% |
27.02% |
| 4 |
ITAJAI |
3712 |
3.36% |
30.39% |
| 5 |
PALHOCA |
3283 |
2.97% |
33.36% |
| 6 |
CHAPECO |
3275 |
2.97% |
36.33% |
| 7 |
CRICIUMA |
3102 |
2.81% |
39.14% |
| 8 |
BRUSQUE |
3060 |
2.77% |
41.91% |
| 9 |
JARAGUA DO SUL |
2894 |
2.62% |
44.54% |
Script Python
plt.style.use('ggplot')plt.rcdefaults()fig, ax = plt.subplots()y_pos = np.arange(len(df_empregos['NOME_MUNICIPIO'].value_counts().head(15)))values = df_empregos['NOME_MUNICIPIO'].value_counts().head(15)segmentos = df_empregos['NOME_MUNICIPIO'].value_counts().keys()[:15]ax.barh(y_pos, values, align='center')ax.set_yticks(y_pos)ax.set_yticklabels(segmentos)ax.invert_yaxis()ax.set_xlabel('Quantidade de Cantidados')ax.set_title('15 cidades com maiores cquantidade de \nCandidatos em Santa Catarina')plt.show()
2.3. Quantidade de Candidatos por Escolaridade
Tópico
Script Python
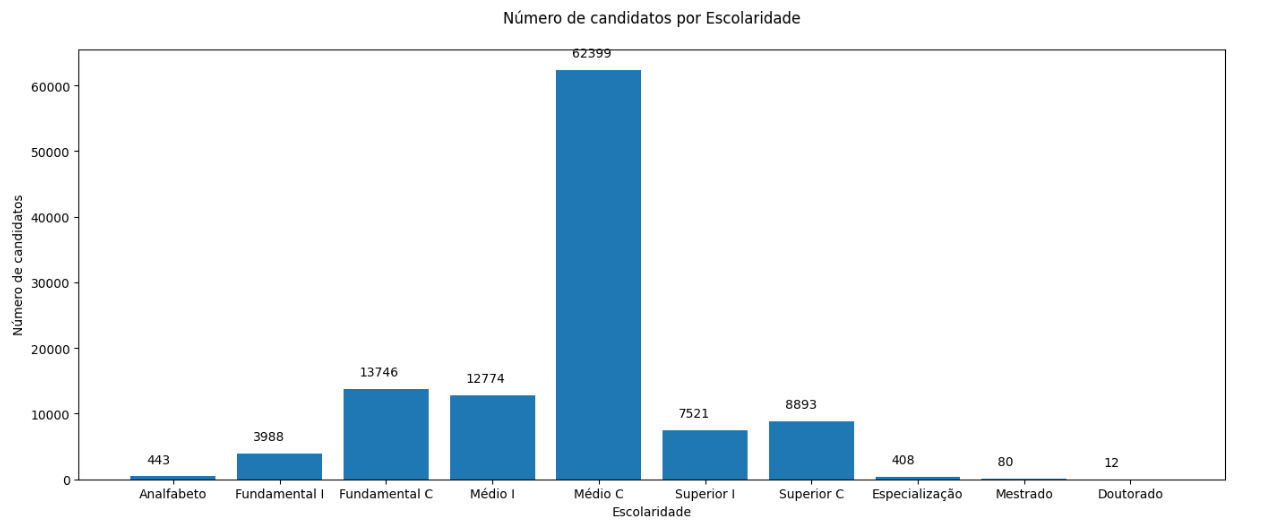
def ordem(x):ordem_esc = {}ordem_esc['Analfabeto'] = 1ordem_esc['Fundamental Incompleto'] = 2ordem_esc['Fundamental Completo'] = 3ordem_esc['Médio Incompleto'] = 4ordem_esc['Médio Completo'] = 5ordem_esc['Superior Incompleto'] = 6ordem_esc['Superior Completo'] = 7ordem_esc['Especialização'] = 8ordem_esc['Mestrado'] = 9ordem_esc['Doutorado'] = 10return ordem_esc.get(x,0)df_escolaridade = pd.DataFrame(df_empregos['ESCOLARIDADE'].value_counts())df_escolaridade = df_escolaridade.reset_index().rename(columns={'index':'Escolaridade', 'ESCOLARIDADE':'Qtd. Candidatos'})df_escolaridade['ordem'] = df_escolaridade['Escolaridade'].apply(ordem)df_escolaridade = df_escolaridade[df_escolaridade['ordem'] != 0]df_escolaridade = df_escolaridade.sort_values('ordem')df_escolaridade.drop('ordem', inplace=True, axis=1)df_escolaridade = df_escolaridade.reset_index(drop=True)print(color.BOLD+"\nRelação de escolaridade com quantidade de candidatos\n")df_escolaridade_s = df_escolaridade.style.set_table_styles(contorno)display(df_escolaridade_s)
| |
Escolaridade |
Qtd. Candidatos |
| 0 |
Analfabeto |
443 |
| 1 |
Fundamental Incompleto |
3988 |
| 2 |
Fundamental Completo |
13746 |
| 3 |
Médio Incompleto |
12774 |
| 4 |
Médio Completo |
62399 |
| 5 |
Superior Incompleto |
7521 |
| 6 |
Superior Completo |
8893 |
| 7 |
Especialização |
408 |
| 8 |
Mestrado |
80 |
| 9 |
Doutorado |
12 |
Script Python
eixo_x = ['Analfabeto', 'Fundamental I', 'Fundamental C', 'Médio I','Médio C','Superior I', 'Superior C', 'Especialização','Mestrado','Doutorado']def addlabels(nivel_esc): for i, val in enumerate(nivel_esc): plt.text(i-0.25,val+2000,val)fig = plt.figure()ax = fig.add_axes([0,0,2,1])ax.bar(eixo_x,df_escolaridade['Qtd. Candidatos'].tolist())addlabels(df_escolaridade['Qtd. Candidatos'].tolist())plt.title("Número de candidatos por Escolaridade\n")plt.xlabel("Escolaridade") plt.ylabel("Número de candidatos") plt.show()
2.4. Percentual de Candidatos que são Estudantes
Tópico
Script Python
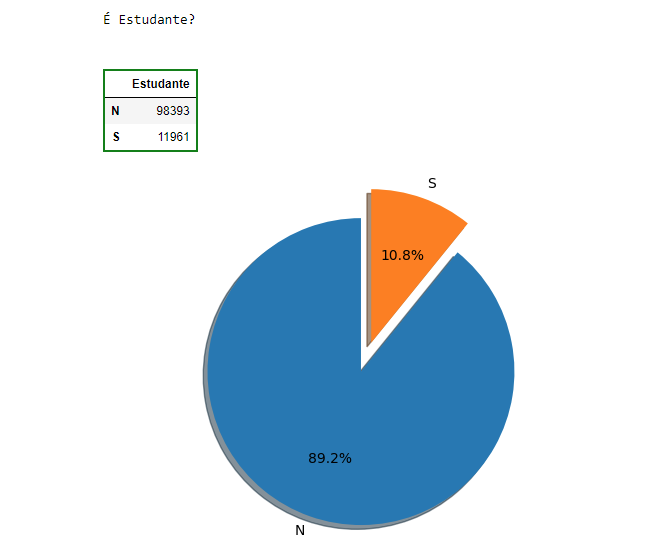
df_estudante = pd.DataFrame(df_empregos['ESTUDANTE'].value_counts()).rename(columns={'ESTUDANTE':'Estudante'})print("\nÉ Estudante?\n")df_estudante_s = df_estudante.style.set_table_styles(contorno)display(df_estudante_s)fig1, ax1 = plt.subplots()explode = [0, 0.2]ax1.pie(df_estudante['Estudante'], explode=explode, labels=df_estudante.index, autopct='%1.1f%%', shadow=True, startangle=90)ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.plt.show()
2.5. Quantidade de Candidatos por Quantidade de Cursos Profissionalizantes
Tópico
Script Python
def cursos(x): if isinstance(x, str): n = len(x.split('|')) return (n if n < 8 else 8) else: return 0df_qt_cursos = pd.DataFrame(df_empregos['CURSOS_PROFISSIONALIZANTES'].apply(cursos).value_counts()).reset_index()df_qt_cursos = df_qt_cursos.rename(columns = {'index':'Cursos Profissionalizantes', 'CURSOS_PROFISSIONALIZANTES':'Candidatos'}).iloc[:,[1,0]]df_qt_cursos_s = df_qt_cursos.style.set_table_styles(contorno_azul)display(df_qt_cursos_s)
| |
Candidatos |
Cursos Profissionalizantes |
| 0 |
95980 |
0 |
| 1 |
8269 |
1 |
| 2 |
2890 |
2 |
| 3 |
1499 |
3 |
| 4 |
758 |
4 |
| 5 |
427 |
5 |
| 6 |
221 |
6 |
| 7 |
191 |
8 |
| 8 |
119 |
7 |
Script Python
maior = 0cursos_prof = []t_pret = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]for emprego in df_empregos.values: aux = emprego[8] qtd_pret = 0 # print(type(aux)) if isinstance(aux, str): aux = aux + "|" ind1 = 0 ind2 = 0 x = len(aux) while ind1 < x: qtd_pret += 1 ind2 = aux.find("|", ind1) if ind2 == 0: ind2 = x + 1 cursos_prof.append(unidecode.unidecode(aux[ind1:ind2].lower())) ind1 = ind2 + 1 t_pret[qtd_pret] += 1 if qtd_pret > maior: maior = qtd_pret else: t_pret[0] += 1
df_x = pd.DataFrame(cursos_prof)print(len(pd.unique(df_x[0])))df_x.value_counts().head(15)
|
Quantidade |
| Cursos Profissionalizante |
|
| informatica basica |
2398 |
| informatica |
722 |
| vigilante |
641 |
| operador de empilhadeira |
389 |
| auxiliar administrativo |
289 |
| administracao |
259 |
| informatica avancada |
210 |
| vendas |
199 |
| secretariado |
199 |
| tecnico em administracao |
173 |
| atendente de farmacia |
165 |
| tecnico em seguranca do trabalho |
156 |
| tecnico em enfermagem |
146 |
| atendimento ao cliente |
145 |
| mopp |
136 |
2.6. Graduações e Quantidade de Candidatos
Tópico
Script Python
import unidecodemaior = 0graduacoes = []t_pret = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]for emprego in df_empregos.values: aux = emprego[9] qtd_pret = 0 if isinstance(aux, str): aux = aux + "|" ind1 = 0 ind2 = 0 x = len(aux) while ind1 < x: qtd_pret += 1 ind2 = aux.find("|", ind1) if ind2 == 0: ind2 = x + 1 graduacoes.append(unidecode.unidecode(aux[ind1:ind2].lower())) ind1 = ind2 + 1 t_pret[qtd_pret] += 1 if qtd_pret > maior: maior = qtd_pret else: t_pret[0] += 1print("\n============================================\n")print("Maior número de graduacoes por candidato: ",maior, "\n")print("Graduações Candidatos")for i in range(len(t_pret)): if t_pret[i] > 0: print (" ", i, "\t", " ", t_pret[i])print("=" * 35, "\n")print ("\nTotal de Graduacoes: ", len(graduacoes))
============================================Maior número de graduacoes por candidato: 5 Graduações Candidatos0 961061 135892 6083 444 65 1===================================
Script Python
df_x = pd.DataFrame(graduacoes)<df_x.value_counts().head(20)
|
0 |
| 0 |
|
| administracao |
1872 |
| direito |
947 |
| pedagogia |
937 |
| ciencias contabeis |
824 |
| educacao fisica |
498 |
| processos gerenciais |
345 |
| engenharia civil |
297 |
| psicologia |
279 |
| logistica |
241 |
| enfermagem |
216 |
| administracao de empresas |
212 |
| recursos humanos |
178 |
| adm |
163 |
| nutricao |
155 |
| gestao comercial |
138 |
| servico social |
129 |
| engenharia de producao |
123 |
| fisioterapia |
120 |
| engenharia mecanica |
117 |
| gestao financeira |
113 |
2.7. Tipo de Habilitação
Tópico
Script Python
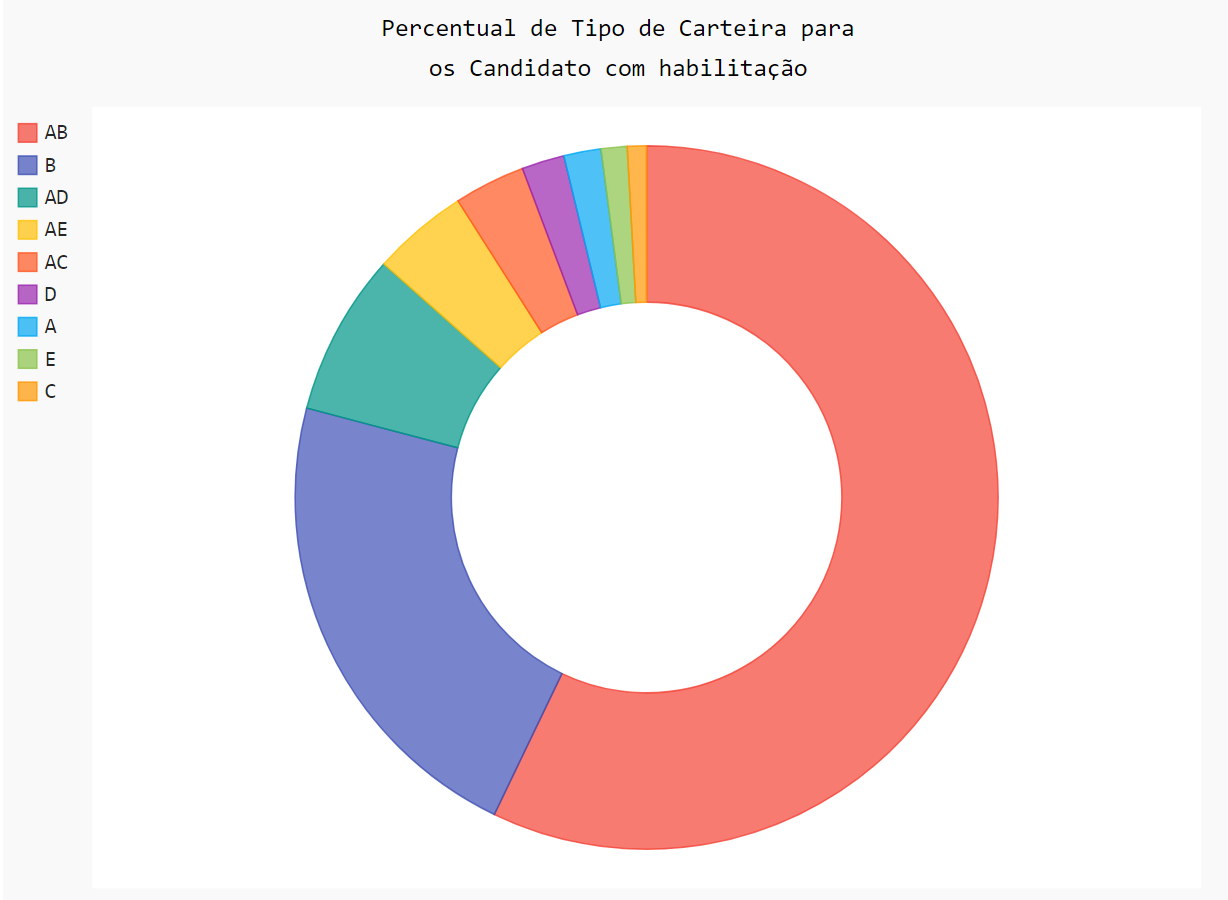
habilitação = df_empregos['HABILITACAO'].value_counts()print("\nPossui que tipo de habilitação?\n")print(habilitação)
Possui que tipo de habilitação?Nenhum 82393AB 15974B 6141AD 2087AE 1237AC 915D 548A 479E 334C 246Name: HABILITACAO, dtype: int64
Script Python
habilitação = habilitação.reset_index()hab = habilitação.copy()hab['index'][hab['index'] != 'Nenhum'] = 'Possuem habilitação'(hab.groupby('index')['HABILITACAO'].sum()/hab['HABILITACAO'].sum()*100).round(2)
indexNenhum 74.66Possuem habilitação 25.34Name: HABILITACAO, dtype: float64
import pygal pie_chart = pygal.Pie(inner_radius = .5) pie_chart.title = 'Percentual de Tipo de Carteira para \nos Candidato com habilitação'pie_chart.add(habilitação.iloc[1,0], habilitação.iloc[1,1])pie_chart.add(habilitação.iloc[2,0], habilitação.iloc[2,1])pie_chart.add(habilitação.iloc[3,0], habilitação.iloc[3,1])pie_chart.add(habilitação.iloc[4,0], habilitação.iloc[4,1])pie_chart.add(habilitação.iloc[5,0], habilitação.iloc[5,1])pie_chart.add(habilitação.iloc[6,0], habilitação.iloc[6,1])pie_chart.add(habilitação.iloc[7,0], habilitação.iloc[7,1])pie_chart.add(habilitação.iloc[8,0], habilitação.iloc[8,1])pie_chart.add(habilitação.iloc[9,0], habilitação.iloc[9,1])pie_chart
2.8. Em relação ao horário pretendido para trabalhar, existe diferença entre escolaridade?
Tópico
Script Python
graf = pd.DataFrame(df_prest['Horario'].value_counts().reset_index())graf.columns = ['Horario','Quantidade']graf1.plot(x='Horario', y='Quantidade', kind = 'bar', color = 'g')plt.title("Opção de Horário")plt.ylabel("Quantidade de Pessoas")plt.xlabel("Período")
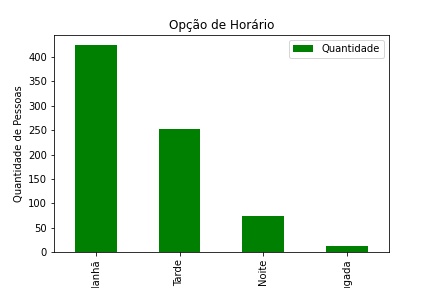
Script Python
graf2.plot(x='Horario', y='Quantidade', kind = 'bar' , color= 'g')plt.title("Opção de Horário")plt.ylabel("Quantidade de Pessoas")plt.xlabel("Período")
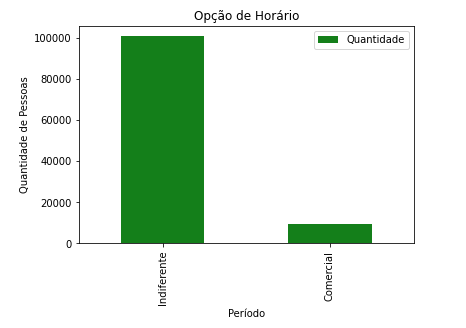
Conforme podemos observar o gráfico acima e a tabela abaixo
aproximadamente, 99.31% da população não possuem preferencia de horário de trabalho.
Script Python
hora_trab = pd.DataFrame(df_prest[['Horario']].value_counts()/df_prest.shape[0]*100).round(4)hora_trab = hora_trab.reset_index().sort_values(by = 0, ascending = False)hora_trab.columns = ['Hora de trabalho', 'Perc.']hora_trab
|
Hora de trabalho |
Perc. |
| 0 |
Indiferente |
90.7336 |
| 1 |
Comercial |
8.5787 |
| 2 |
Manhã |
0.3826 |
| 3 |
Tarde |
0.2277 |
| 4 |
Noite |
0.0666 |
| 5 |
Madrugada |
0.0108 |
2.9 Proporção Em relação ao Idiomas
Tópico
Script Python
# Idiomasmaior = 0idiomas = []t_pret = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]for emprego in df_prest.values: aux = emprego[12] qtd_pret = 0 if isinstance(aux, str): aux = aux + "|" ind1 = 0 ind2 = 0 x = len(aux) while ind1 < x: qtd_pret += 1 ind2 = aux.find("|", ind1) if ind2 == 0: ind2 = x + 1 idiomas.append(unidecode.unidecode(aux[ind1:ind2].lower())) ind1 = ind2 + 1 t_pret[qtd_pret] += 1 if qtd_pret > maior: maior = qtd_pret else: t_pret[0] += 1print("\n============================================\n")print("Maior número de idiomas por candidato: ",maior, "\n")print("Idiomas Candidatos")for i in range(len(t_pret)): if t_pret[i] > 0: print (" ", i, "\t", " ", t_pret[i])print("=" * 35, "\n")print ("\nTotal de idiomas: ", len(idiomas))
============================================Maior número de idiomas por candidato: 5 Idiomas Candidatos0 1084821 18862 6233 874 75 4===================================
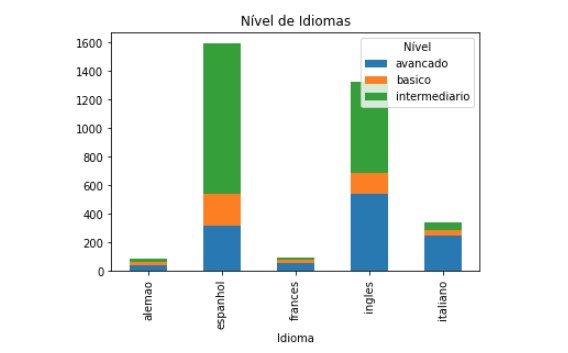
Entendendo o nível de cada idioma.
Script Python
df_x = pd.DataFrame(idiomas)valores = list(df_x.value_counts())Idioma = list(df_x[0].unique())df_idioma = pd.DataFrame({'Idioma': Idioma, "Qtd": valores})df_idioma['Nível'] = ""for i in range(df_idioma.shape[0]): n = df_idioma.loc[i,'Idioma'].find(' ') df_idioma.loc[i,'Nível'] = df_idioma.loc[i,'Idioma'][n+1:] df_idioma.loc[i,'Idioma'] = df_idioma.loc[i,'Idioma'][:n]df2 = df_idioma.groupby(['Idioma', 'Nível'])['Qtd'].sum().unstack('Nível').fillna(0)df2.plot(kind='bar', stacked=True, title = 'Nível de Idiomas', mark_right = True)
Script Python
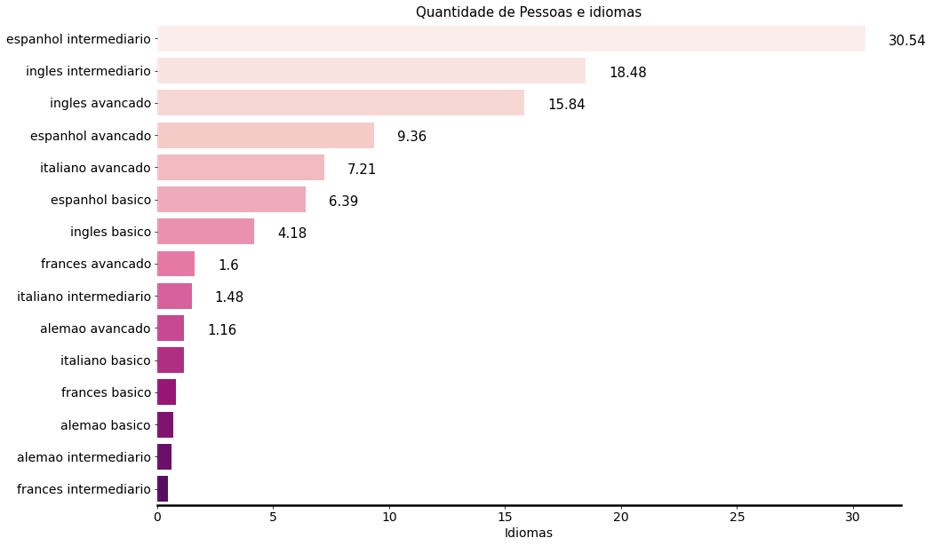
colunas = str(df_x.index)colunas = colunas.replace('MultiIndex([(',"").replace(')','').replace('"','').replace('\n','').replace('(','').replace(']','').replace("'",'').replace(",,",',')colunas = colunas.strip()valores = list(df_x.value_counts())Idioma = list(df_x[0].unique())df_idioma = pd.DataFrame({'Idioma': Idioma, "Qtd. Pessoas": valores})df_idioma['Qtd. Pessoas'] = (df_idioma['Qtd. Pessoas']/df_idioma['Qtd. Pessoas'].sum()*100).round(2)df_idioma.set_index('Idioma', inplace = True)quantidade = []for i in df_idioma['Qtd. Pessoas']: quantidade.append(i)posicao = []for i in range(0,10,1): posicao.append(i)
#criando uma figure, axes, alterando tamanhofig, ax = plt.subplots(figsize=(15,10))#criando o gráfico de barrassns.barplot(y= df_idioma.index, x= df_idioma['Qtd. Pessoas'], ax=ax, data=df_idioma, palette='RdPu')#adicionando títuloax.set_title("Quantidade de Pessoas e idiomas", fontdict={'fontsize':15})#mudando e nome e tamanho do label xax.set_xlabel('Idiomas', fontdict={'fontsize':14})#mudando tamanho do label eixo yax.set_ylabel('')#mudando tamanho dos labels dos ticksax.tick_params(labelsize=14)#aumentando espessura linha inferiorax.spines['bottom'].set_linewidth(2.5)#remoção dos outros três axisfor axis in ['top', 'right', 'left']: ax.spines[axis].set_color(None)#remoção dos ticksax.tick_params(axis='x', labelleft=False, left=None)#Colocando a quantidade em cada barrafor i in range(15): ax.text(y=posicao[i]+0.2, x=quantidade[i]+1, s=str(quantidade[i]), fontsize=15)#otimizar espaço da figurefig.tight_layout();
2.10 Qual Região mais representativo em relação ao PIB?
Tópico
Script Python
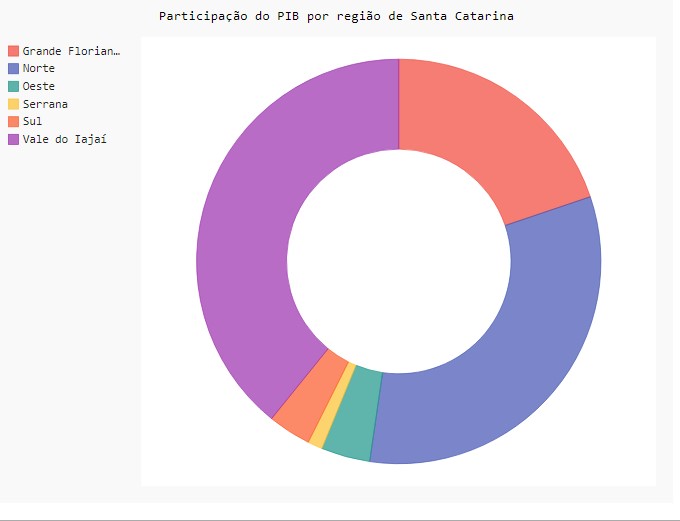
pd_reg_pib = pd.DataFrame((df_prest.groupby('Regiao')['pib'].sum()/(df_prest['pib'].sum())*100).round(2)).reset_index()
|
Regiao |
pib |
| 0 |
Grande Florianópolis |
19.82 |
| 1 |
Norte |
32.48 |
| 2 |
Oeste |
3.91 |
| 3 |
Serrana |
1.18 |
| 4 |
Sul |
3.44 |
| 5 |
Vale do Iajaí |
39.17 |
Script Python
lebels = list(pd_reg_pib['Regiao'])pib = list(pd_reg_pib['pib'])pie_chart = pygal.Pie(inner_radius = .5) pie_chart.title = 'Participação do PIB por região de Santa Catarina'pie_chart.add(lebels[0], pib[0]) pie_chart.add(lebels[1], pib[1]) pie_chart.add(lebels[2], pib[2]) pie_chart.add(lebels[3], pib[3]) pie_chart.add(lebels[4], pib[4]) pie_chart.add(lebels[5], pib[5]) pie_chart
3. Teste de Hipótese
3.1 O salário médio de quem pretende estágio, é menor do que de quem não aceita estágio?
Tópico
Observar-se como estão distribuido o salário médio em relação as profissões:
Script Python
sal_media = df_cbo_cidadao.groupby('id_cidadao')[['Média Salarial']].agg(['min','mean','max','std'])sal_media = sal_media.stack(level = 0)sal_media.reset_index(inplace = True)sal_media = sal_media[['min','mean','max','std']]sal_media.describe()
|
min |
mean |
max |
std |
| count |
110830.000000 |
110830.000000 |
110830.000000 |
109104.000000 |
| mean |
1469.924951 |
1675.268167 |
1970.384931 |
197.263764 |
| std |
533.645633 |
687.064514 |
1116.369441 |
383.647013 |
| min |
1100.000000 |
1115.820000 |
1115.820000 |
0.000000 |
| 25% |
1273.910000 |
1343.815455 |
1402.960000 |
10.021851 |
| 50% |
1329.950000 |
1444.379250 |
1620.670000 |
69.324050 |
| 75% |
1446.800000 |
1728.010000 |
1961.380000 |
200.643891 |
| max |
22168.280000 |
22168.280000 |
22168.280000 |
10072.421064 |
Script Python
sal_media = df_prest.join(sal_media)sal_media['mean'].dropna(inplace = True)sns.kdeplot(sal_media['mean'], shade=True)plt.suptitle('Histograma do salário Médio por Profissão')plt.xlabel('Média Salarial')bplt.show()
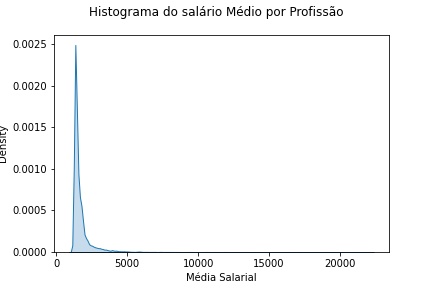
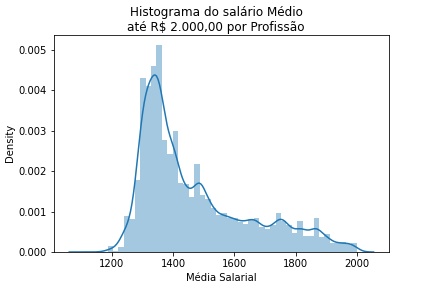
Script Python
sal_media['mean'].describe()
count 110830.000000mean 1675.268167std 687.064514min 1115.82000025% 1343.81545550% 1444.37925075% 1728.010000max 22168.280000Name: mean, dtype: float64
Script Python
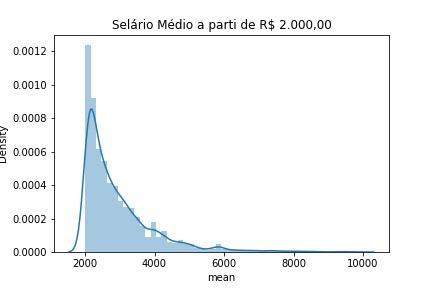
grafic2 = sal_media[(sal_media['mean']>2000) & (sal_media['mean']<10000)]sns.distplot(grafic2['mean'])plt.title('Selário Médio a parti de R$ 2.000,00')plt.show()
Script Python
salario = pd.DataFrame( [sal_media[sal_media['mean']<2000].shape[0]/sal_media.shape[0]*100,sal_media[sal_media['mean']>=2000].shape[0]/sal_media.shape[0]*100], ['Abaixo','Acima']).reset_index()salario.columns = ['Salário (R$ 2.000,00)','Percentual']salario.Percentual = salario.Percentual.round(2)salario
|
Salário (R$ 2.000,00) |
Percentual |
| 0 |
Abaixo |
86.28 |
| 1 |
Acima |
13.72 |
Script Python
df_sal_media = df_prest.join(sal_media)df_sal_media['mean'].dropna(inplace = True)c_estagio = sal_media[sal_media['Estagio'] == "S"]s_estagio = sal_media[sal_media['Estagio'] == "N"]sal_media.groupby('Estagio')[['min','mean','max','std']].mean()
|
min |
mean |
max |
std |
| Estagio |
|
|
|
|
| N |
1469.847048 |
1675.033252 |
1969.956665 |
197.102298 |
| S |
1474.869738 |
1690.179022 |
1997.568470 |
207.495582 |
Script Python
ax = sns.boxplot(x = 'max', data = c_estagio[(c_estagio['mean']< 5000)], orient = 'h')ax.figure.set_size_inches(12, 4)ax.set_title('Salário Médio para aquele que aceitam estágio', fontsize=18)ax.set_xlabel('Valores Reais', fontsize=14)ax
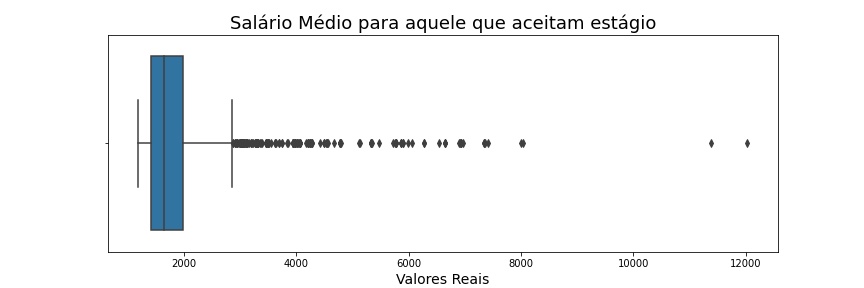
Script Python
ax = sns.boxplot(x = 'max', data = s_estagio[(s_estagio['mean']< 5000)], orient = 'h')ax.figure.set_size_inches(12, 4)ax.set_title('Salário Médio para aquele que aceitam estágio', fontsize=18)ax.set_xlabel('Valores Reais', fontsize=14)ax
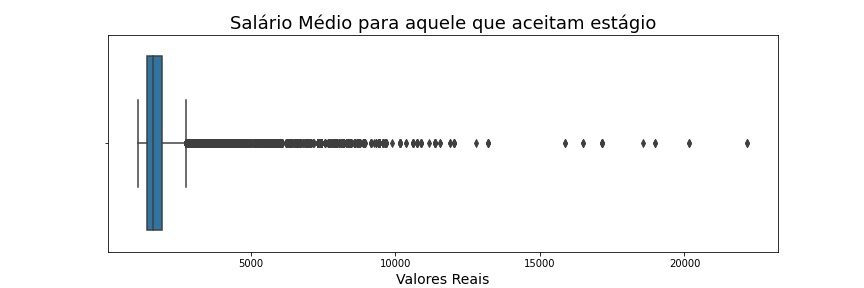
Script Python
sns.boxplot(x='Estagio', y='max', data=df_sal_media[df_sal_media['max'] < 2000])plt.title('Boxplot do salário Máximo pretendido\na categoria de estágio', fontsize=18)
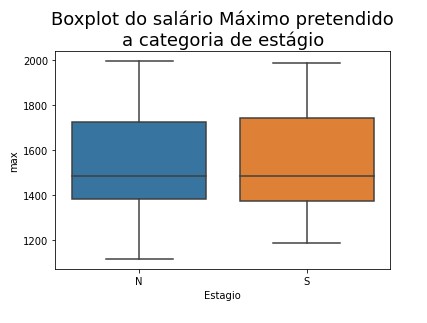
Script Python
r = ranksums(c_estagio['mean'], s_estagio['mean'])print('O valor do p-value é {}'.format(r.pvalue))
O valor do p-value é 0.23756193939961712
Como o teste deu um valor p-value maior que 0.05, podemos rejeitar a hipótese nula e aceitar a hipótese que o salário médio
das pretenções salariais em relação a média de salário da profissão pretendida é igual para as pessoas que aceitam e rejeitam estagiar.
3.2 Em relação ao piso salarial máximo é igual para quem aceita e não aceita estágio?
Tópico
Script Python
piso_salarial = df_cbo_cidadao.groupby('id_cidadao')['Piso Salarial'].agg(['min','median','mean','max','std'])piso_salarial = df_prest.join(piso_salarial)c_estagio = piso_salarial[piso_salarial['Estagio'] == "S"]s_estagio = piso_salarial[piso_salarial['Estagio'] == "N"]r = ranksums(c_estagio['max'], s_estagio['max'])print('O valor do p-value é {}'.format(r.pvalue))
O valor do p-value é 0.0001815241562979713
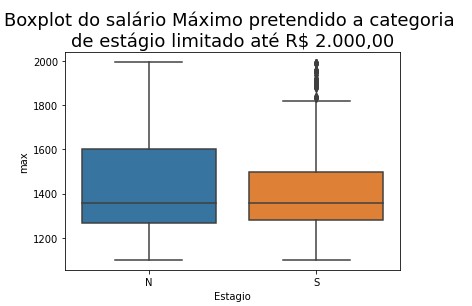
Conclusão: Conforme podemos observar no teste de hipótese, podemos rejeitar a hipótese
nula e aceitar que nesta amostragem o salário médio dos pretendente que aceita estagiar seja diferente dos candidatos que não aceitam.
Porém podemos aceitar a hipótese nula e considerar que o piso salarial máximo, para quem não aceita estagiar é maior em relação a participante amostral
dos candidados que aceitam estagiar
3.3 O teto salarial para quem tem nível de escolaridade de superior para cima, é maior do que para quem não tem curso superior completo?
Tópico
Script Python
sal_teto = df_cbo_cidadao.groupby('id_cidadao')[['Teto Salarial']].agg(['max','std'])sal_teto = sal_teto.stack(level = 0)sal_teto.reset_index(inplace = True)sal_teto = sal_teto[['max','std']]sal_teto = df_prest.join(sal_teto)
sns.boxplot(x='Nivel_esc', y='max', data=piso_salarial[piso_salarial['max']<10000])
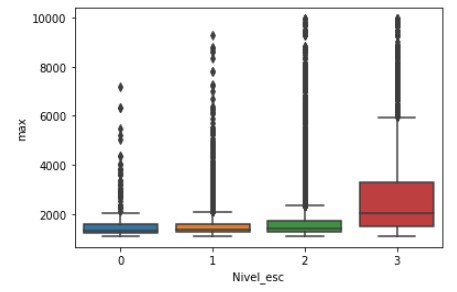
Script Python
pd.DataFrame(piso_salarial[['ESCOLARIDADE','Nivel_esc']].value_counts())
|
|
0 |
| ESCOLARIDADE |
Nivel_esc |
|
| Médio Completo |
2 |
62794 |
| Fundamental Completo |
1 |
13838 |
| Médio Incompleto |
2 |
12853 |
| Superior Completo |
3 |
8945 |
| Superior Incompleto |
3 |
7576 |
| Fundamental Incompleto |
1 |
4041 |
| Analfabeto |
0 |
446 |
| Especialização |
3 |
411 |
| Nenhum |
0 |
93 |
| Mestrado |
3 |
80 |
| Doutorado |
3 |
12 |
Script Python
classe = pd.DataFrame(piso_salarial['Nivel_esc'].value_counts()/piso_salarial.shape[0]*100).round(2).reset_index().sort_values(by = 'index', ascending = False)classe.columns = ['Classificação Escolaridade','Percentual da População']classe
|
Classificação Escolaridade |
Percentual da População |
| 2 |
3 |
15.32 |
| 0 |
2 |
68.10 |
| 1 |
1 |
16.09 |
| 3 |
0 |
0.49 |
Teste de Hipótese entre os candidatos que possuem ensino superior e os candidade que posuuem até o ensino médio
O valor do p-value é 0.0
Script Python
c_superior = piso_salarial[piso_salarial['Nivel_esc'] == 3]s_superior = piso_salarial[piso_salarial['Nivel_esc'] != 3]r = ranksums(c_superior['max'], s_superior['max'])print('O valor do p-value é {}'.format(r.pvalue))
Conforme podemos observar o teste de hipótese o resultado do p-value, não podemos rejeitar a hipótese nula, e em relação
a amostra trabalhada, o salário máximo, para que possue salário superior ou acima, é maior do que os candidatos que não possuem ensino superior.
3.4 A média salarial por região e por nível de escolaridade são igual ou estatísticamente são diferentes?
Tópico
Script Python
pd.DataFrame(piso_salarial[['Regiao','Nivel_esc']].value_counts()/piso_salarial.shape[0]*100).round(2).sort_values(by = [0,'Nivel_esc'], ascending = False)
|
|
Percentual |
| Regiao |
Nivel_esc |
|
| Vale do Iajaí |
2 |
18.87 |
| Norte |
2 |
15.23 |
| Grande Florianópolis |
2 |
12.70 |
| Sul |
2 |
9.96 |
| Oeste |
2 |
8.43 |
| Vale do Iajaí |
1 |
4.30 |
| 3 |
3.88 |
| Norte |
1 |
3.81 |
| Grande Florianópolis |
3 |
3.48 |
| Norte |
3 |
3.21 |
| Serrana |
2 |
2.90 |
| Oeste |
1 |
2.90 |
| 3 |
2.29 |
| Grande Florianópolis |
1 |
2.06 |
| Sul |
1 |
2.04 |
| 3 |
1.85 |
| Serrana |
1 |
0.98 |
| 3 |
0.62 |
| Vale do Iajaí |
0 |
0.14 |
| Oeste |
0 |
0.13 |
| Norte |
0 |
0.08 |
| Grande Florianópolis |
0 |
0.06 |
| Sul |
0 |
0.05 |
| Serrana |
0 |
0.02 |
Script Python
classes = [0,1300, 1400,1600,1800,50000]
labels = ['Até R$ 1300,00','De R$1.300,00 a R$ 1.400,00',
'De R$1.400,00 a R$ 1.600,00', 'De R$1.600,00 a R$ 1.800,00', 'Acima de 2 s.m']
classe = pd.cut(x = sal_media['mean'], bins = classes, labels = labels)
sal_media['Classificação'] = classe
sal_media['Classificação'].value_counts(sort = False)
Até R$ 1300,00 9185De R$1.300,00 a R$ 1.400,00 36853De R$1.400,00 a R$ 1.600,00 28174De R$1.600,00 a R$ 1.800,00 13819Acima de 2 s.m 22799Name: Classificação, dtype: int64
Script Python
labels = ['Vale do Iajaí', 'Norte', 'Sul', 'Serrana', 'Oeste', 'Grande Florianópolis']mapping = {Região: i for i, Região in enumerate(labels)}key = cid_claf['Região'].map(mapping)cid_claf = cid_claf.iloc[key.argsort()]cid_claf.plot(kind='bar', x = 'Região')plt.ylabel('Quantidade de Pessoas')plt.xlabel('Região')plt.title("Pretenção salarial por Salário mínimo e \npor Região de Santa Catarina")plt.show()
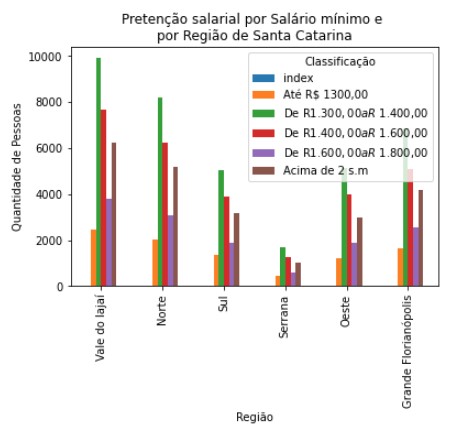
Abaixo podemos observar o salário médio por Região:
Script Python
piso_salarial.groupby('Regiao')['mean'].mean().round(2)
RegiaoGrande Florianópolis 1545.81Norte 1543.43Oeste 1495.24Serrana 1467.28Sul 1513.60Vale do Iajaí 1541.30Name: mean, dtype: float64
E abaixo os resultados dos teste de hipótese de média salarial entre as regiões:
Script Python
reg_g = piso_salarial[piso_salarial['Regiao'] == 'Grande Florianópolis']reg_n = piso_salarial[piso_salarial['Regiao'] == 'Norte']reg_o = piso_salarial[piso_salarial['Regiao'] == 'Oeste']reg_se = piso_salarial[piso_salarial['Regiao'] == 'Serrana']reg_su = piso_salarial[piso_salarial['Regiao'] == 'Sul']reg_vi = piso_salarial[piso_salarial['Regiao'] == 'Vale do Iajaí']print("Comparando o Salário Médio entre as Regiões")print("===========================================\n")r = ranksums(reg_g['mean'], reg_n['mean'])print('Entre Grande Florianópolies e a Reigão Norte \n* O valor do p-value é {}\n'.format(r.pvalue))print("--------------------------------------------\n")r = ranksums(reg_o['mean'], reg_se['mean'])print('Entre Região Oeste e a Reigão Serrana \n* O valor do p-value é {}'.format(r.pvalue))print("--------------------------------------------\n")r = ranksums(reg_su['mean'], reg_vi['mean'])print('Entre Região Sul e a Reigão do Vale de Itajaí \n* O valor do p-value é {}'.format(r.pvalue))print("===========================================")
Comparando o Salário Médio entre as Regiões===========================================Entre Grande Florianópolies e a Reigão Norte * O valor do p-value é 7.504534489971003e-35--------------------------------------------Entre Região Oeste e a Reigão Serrana * O valor do p-value é 4.112682802233225e-12--------------------------------------------Entre Região Sul e a Reigão do Vale de Itajaí * O valor do p-value é 3.5568721380093584e-14===========================================
Devemos rejeitar a hipótese nula, não podendo afirmar que a média do piso salarial das prentenção são diferente por Região
dentro do Estado de Santa Catarina, conforme nossa amostragem.
Script Python
fig = px.treemap(prest_media_salarial, path=[px.Constant("Mapeamento por: Região, Escolaridade, e Disponibilidade de Horário para trabalho"),'Regiao_y', 'ESCOLARIDADE','Horario'], values='max')fig.update_traces(root_color="lightgrey")fig.update_layout(margin = dict(t=50, l=25, r=25, b=25))fig.show()

4. Os cargos mais procurados no Estado de Santa Catarina
Script Python
prof = list(df_cbo_cidadao['Cargo'].value_counts().head(50).index)quantidade = list(df_cbo_cidadao['Cargo'].value_counts().head(50).values)plt.figure(figsize = (20,25))plt.barh(prof, quantidade, color = 'green')plt.title('50 Profissões mais escolhidas', fontsize=24)plt.yticks(fontsize=18)plt.xticks(fontsize=28)plt.xlabel('Quantidade', fontsize=28)plt.ylabel('Profissão', fontsize=28)plt.show()
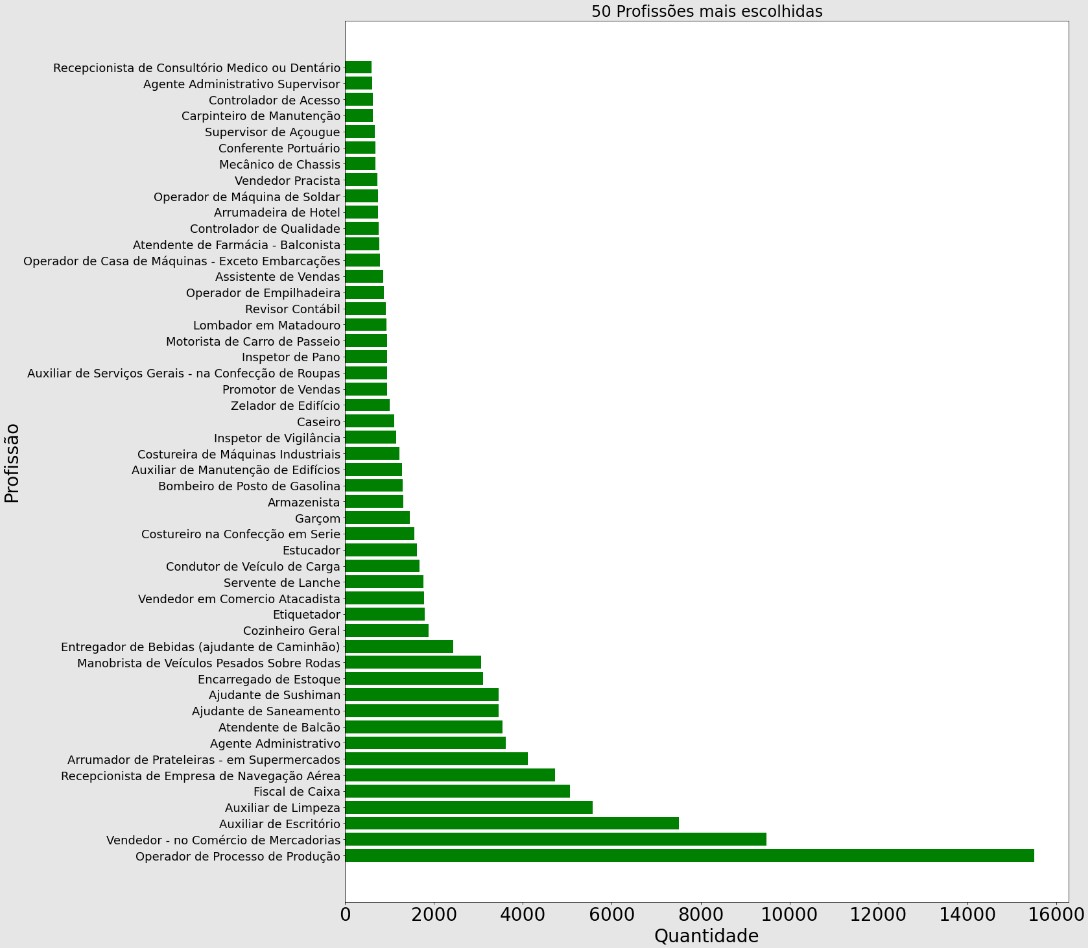
Uma outra forma de demonstrar os empregos mais procurados.
Script Python
df_cbo_cidadao['Cargo'] = df_cbo_cidadao['Cargo'].replace(" ",'_')emprego = []for num in range(df_cbo_cidadao.shape[0]): name = df_cbo_cidadao.loc[num,'Cargo'].replace(" ",'_') emprego.append(name) words = emprego all_words = ','.join(w for w in words)stopwords = set(STOPWORDS)wordcloud = WordCloud(stopwords=stopwords, background_color='white', width=1600, #mask=mask1, height=800, max_words=500, max_font_size=1000, min_font_size=1).generate(all_words)#configurando forma de apresentação do gráfico e apresentando no notebook.fig, ax = plt.subplots(figsize=(16,8))ax.imshow(wordcloud, interpolation='bilinear')ax.set_axis_off()plt.imshow(wordcloud);
